1. Introduction
For several reasons, this will probably be the last post on the theme "ReSharper VS Eclipse". First of all: This was never intended as a blog series, but the content was too much to fit in one post. Secondly: I have a lot of other stuff that I would love to write about. It would however be fun to make more of a ReSharper-focused blog series. This is something that I'll hopefully be able to do at my new Employment at
Edument.
For now, however, I'll try to wrap this up. In this post I'll cover a little about unit test integration as well as a few handy shortcuts which I use more or less everyday now. Again. Keep in mind that I'm using the IntelliJ IDEA keyboard mapping since it felt more intuitive for me. In Eclipse, I'm using the default keymap settings (Except that I've changed the Alt+F6 mapping to Alt+Tab).
In order to have something to test, I wrote a small application using test driven development (
TDD) for this article. It's a small, very simple, string parser. It takes input on the form of "2+3-1" and calculates the result. A parser such as this is quite gratifying to develop using TDD principles. Unit tests is a very handy way of checking different input combinations. This kind of testing also helps you catch errors such as broken existing functionality (which would cause your older tests to fail).
I'm not going to delve to deep into TDD in this article. Nor am I going to explain how unit testing works. These are interesting areas, but I don't want to lose focus.
... I might have to do an article about TDD in the future ;)
2. Testing out of the box
You usually have some choice in selecting your unit testing framework. There's all kinds of xUnit-testers for different languages. For instance, JUnit for Java, NUnit for .NET, CppUnit for C++ and SUnit for Smalltalk, which seem to have started the chain of unit testers to begin with. There's a lot more than the ones I mentioned here, but you get the idea.
For Java, I usually end up with
JUnit. There's another variant called
TestNG which looks good too (and comes with an Eclipse plugin). Since testing with JUnit is supported directly through the Eclipse IDE without having to install any extra plugins (See figure 1), this is the one I prefer (even when doing
Android testing).
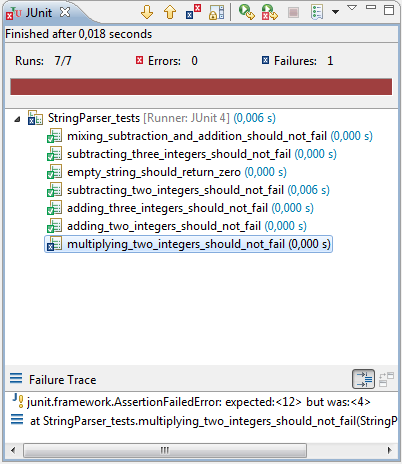 |
| Figure 1: The Eclipse JUnit Test Runner |
For .NET, I exclusively use
NUnit. Microsoft have their own test framework, containing the MSTest unit tester, but I have to admit: I haven't really looked that hard at it since NUnit works well (for a comparison between the two, read
The Bare Bones Coder's blog). By default, Visual Studio does not contain an environment to support NUnit test execution. You usually run a separate NUnit application where you see your test results after execution. Even though the NUnit test runner is a very good application, I prefer to be able to contain as much of my tools as possible inside the IDE (Which is why I use Eclipse when doing Java - There's a plugin for everything). Even though Visual Studio does not support NUnit to start with, ReSharper solves this problem for us: We get the
Unit Test Explorer as well as a
Unit Test Sessions window (see figure 2 and 3)
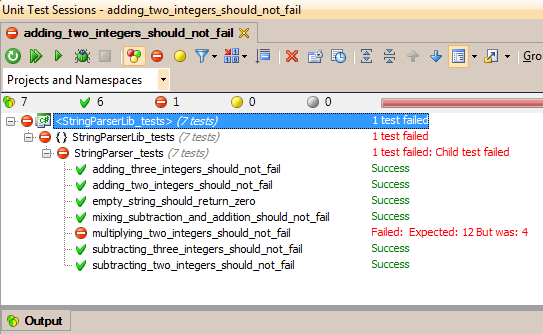 |
| Figure 2: The Unit Test Sessions Window in VS via ReSharper 6 |
The Unit Test Explorer (Figure 3) is a list containing all of your tests, while the Sessions window (figure 2) is where you actually run all tests in a session. Sessions can be configured to contain different combinations of unit tests, which gives you a great deal of control when different tests are run.
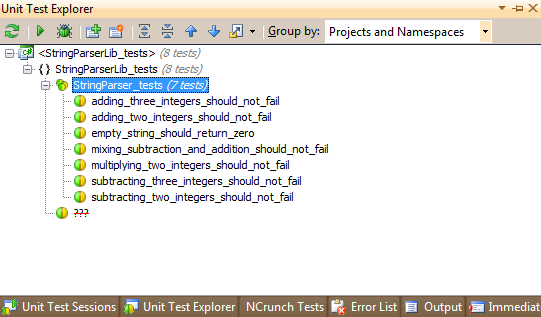 |
| Figure 3: The Unit Test Explorer in VS via ReSharper 6 |
The of the test names gives you an idea of what the parser can do and what it can't. I implemented it up to the point where integer addition and subtraction works. The parser takes strings on the form "2+3-1+2" and returns the correct result. As you can see in both JUnit and the ReSharper unit test session, multiplication is not implemented, causing the test to fail.
3. Shortcuts when testing
3.1 - Eclipse
The first thing that I want to be able to do is to run my unit tests in an easy manner. In Eclipse, you could select your
Project Explorer, right click on the project containing your tests, and select
Run As and then
JUnit Test. Or, as you can see in figure 4, you could use the keyboard chord
Alt+Shift+X, T to run the tests. This is of course the preferred method compared to clicking through menus.
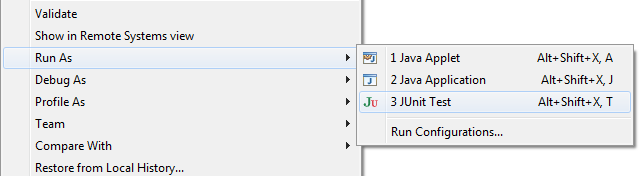 |
| Figure 4: Running the JUnit test project inside Eclipse |
If not already opened, this causes the JUnit test runner tab to open in Eclipse. You get a failure trace containing the JUnit output and some basic navigation functionality such as navigate to the next/previous test which failed. You can also select to show failing tests only and to rerun tests. Reruns can be set to either run everything again (same order as before) or by prioritizing failed tests higher (run all failed tests first, then everything else).
Now, the
Alt+Shift+X, T command seems to be running the unit tests in the current file. You CAN run all unit tests in a specific project, or only one certain unit test. The problem is, that this is done by right clicking the folder or project or method etc. where the test or tests reside. It's the same commando everywhere (Alt+Shift+X, T), but when you use the keyboard shortcut, it's typically from inside the editor, which will only run the tests in the current file. So, if I want to run a specific test only, I have to find the method, right click it and select "Run as JUnit Test". If I want to run all tests in a specific test fixture, I have to either navigate to the class and press Alt+Shift+X, T or Select "Run As -> JUnit Test" on the class. If I have
several test fixtures and want to run all tests in a project, I have to select "Run As -> JUnit Test".
If there's another shortcut for these things in Eclipse, I have completely missed them. If so: please enlighten me, since I consider this to be a major drawback. I might be wrong here, and if so, I'm more than happy to correct the article.
3.2 - ReSharper/VS
In ReSharper, you have a couple of different options. First of all, you have the equivalence of the Eclipse command by pressing the keyboard chord
Ctrl+T, R which runs all unit tests in the current file. The rest of the commands can be seen in figure 5.
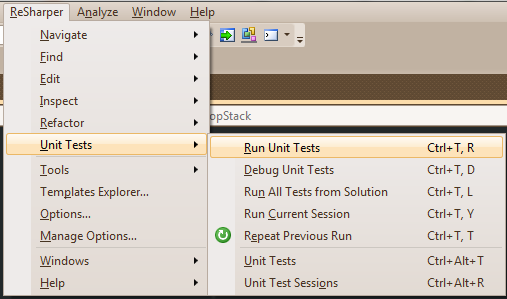 |
| Figure 5: ReSharper Unit Test Commands |
As in Eclipse, you have the ability to rerun tests as well as some session based shortcuts. You also have the ability to bring up the unit test explorer (
Ctrl+Alt+T) and the unit test sessions window (
Ctrl+Alt+R).
One that's widely used by me is the
Run All Tests from Solution. You could press
Ctrl+T, L to accomplish this. But I actually use the actual menu item (through shortcuts though). Look at the sequence you have to press in order to reach this command. First of all,
Alt to focus on the menu bar. Then
R to navigate to the ReSharper menu,
U to select the Unit Tests sub menu and lastly
N to select
Run All Tests from Solution. So. You simply press
Alt and type
RUN. It's subtle, but it's there. This is the kind of things that I really like.
5. More refactoring and navigation options
Since this is the last post on the theme, I'm going to try and wrap this up by naming a few of my favorite shortcuts.
5.1 - Go to Type / Open Type
Opens the specified type. Both ReSharper and Eclipse gives you a menu where you simply start writing the type name and presses enter. In ReSharper, it's called
Go to Type and has the shortcut
Ctrl+N while it's called
Open Type in Eclipse and has the shortcut
Ctrl+Shift+B.
Commands closely related to this one which I use often includes ReSharper's Go to File (
Ctrl+Shift+N) and Eclipse's Open Resource (
Ctrl+Shift+R). A nice feature in both systems is that you can enter the capital letters of a type name when searching. For instance, to find the class StringParser, it's sufficient to write "SP" as the search term.
5.2 - Introduce variable / Extract local variable
Comes in handy quite often for me. It's called
Introduce variable in ReSharper (Shortcut:
Ctrl+Alt+V) and
Extract local variable in Eclipse (Shortcut:
Alt+Shift+L). It assigns the return value from a method (or similar) to a new variable (for instance, when calling a method and never assigning the return value, this is an option).
5.3 - Recent files
This is one of the navigation options that doesn't really have a equivalence in both systems. In ReSharper, you have the "Recent Files" list which you bring up by pressing
Ctrl+E. You can write search terms here too, just as in the "Go to Type" feature.
Except the "Recent Files" area on the file menu, Eclipse doesn't really have a counterpart to this. It does however have a couple of related commands: You have the ability to switch between recently edited files by pressing
Alt+Left and
Alt+Right (ReSharper has a similar to this one: Go to last edit location,
Ctrl+Shift+Backspace). Furthermore, by pressing
Ctrl+F6 (Which I have changed to Ctrl+Tab in my setup) you can switch between currently open editors, and by pressing
Ctrl+E you can even add a search term when switching between open editors.
5.4 - Refactoring
ReSharper has a
Refactor this menu which you can bring up by pressing
Ctrl+Shift+R. Most of the items on this menu has shortcuts of its own too. In Eclipse, you get the
Refactor quick menu by pressing
Alt+Shift+T. Both systems have a lot of operations in common here. This includes the ability to extract superclasses, interfaces and methods, introduce local or field variables as well as changing declarations to use supertypes where possible.
5.5 - Miscellaneous
I can think of one shortcut in Eclipse which is quite useful (and, as far as I know, doesn't exist in ReSharper). By pressing
Ctrl+Shift+L, you can bring up an entire reference for all keyboard shortcuts. It's not a necessity, but it IS without a doubt useful. Pressing
Ctrl+Shift+L again brings up the settings page where you can change the default shortcuts.
Other than this, both ReSharper and Eclipse has a lot of functionality for navigating which I haven't covered yet, such as navigating to base symbols (where the symbol is either a method or a class etc.) which is done through
Ctrl+U in ReSharper (can't find it in Eclipse. I usually end up pressing F3 for
Go to declaration). You can navigate in the opposite direction too (from base to implementation) by using
Go to derived symbols in ReSharper (Shortcut:
Ctrl+Alt+B). In Eclipse, I usually use the
Quick Type Hiearchy for this by pressing
Ctrl+T, which shows the inheritance tree for a particular class.
5. Some reflections on the learning aspect
I have just scraped the surface of both ReSharper and Eclipse. Personally, I use a lot more shortcuts than I've been able to cover in three posts. There's shortcuts for code generation such as creating constructors, wrapping code in try/catch and much, much more. But it takes time to learn everything.
One of the tips I got (can't really remember from where) when I started using ReSharper was to print a copy of the keymapping and keep near my computer at all times (And, in Eclipse: Press
Ctrl+Shift+L). While I think that this has helped me a lot so far, It's also important not to get ahead of yourself. It's both fun and good to try different shortcuts out just to see what happens. This gives you an idea of what the environment CAN do (which is an important grasp to have), but trying 15-20 commands in as many minutes will not make them stick. Instead, let it come naturally by using shortcuts when applicable. Learning is always easier when you have a reason to learn.
Furthermore, when a command that you're just learning IS applicable, try to force yourself to actually use it (preferably through keyboard shortcuts without touching the mouse at all). Piece by piece, you'll construct your own "library" of useful shortcuts which you'll be dependent upon in order to be quick and precise. As John Dewey said:
"Learning by Doing" ;)
6. And, finally...
The only thing I can really say is that I'm going to continue use Eclipse whenever I'm creating something in Java. It's a great environment with lots of functionality. Depending on mood and which OS I'm sitting in I sometimes use Eclipse for C++ development too. Eclipse is big on refactoring and best practices (Who knows: It might have helped that
Erich Gamma has been involved in Eclipse - Design Patterns anyone?)
Whenever I'm creating something in C# however, I'm going to use ReSharper in Visual Studio. I had a small period of time (couple of days) between where my ReSharper trial ended and I obtained my actual license. During these days, Visual Studio felt much harder to use. It might (perhaps) have helped if I had used the VS keymap instead of the IntelliJ one since I've had at least some of the same shortcuts. But all in all: Visual Studio without ReSharper felt a little like bread without butter (Or some other more meaningful analogy, but I'm hungry right now).
| Functionality |
Eclipse |
ReSharper |
| Go to declaration |
F3 |
Ctrl+B |
| Rename in file |
Ctrl+2, R |
F2 |
| Rename everywhere |
Alt+Shift+R |
F2 |
| Run unit tests in file |
Alt+Shift+X, T |
Ctrl+T, R |
| Run ALL unit tests |
- |
Ctrl+T, L or Alt+RUN |
| Go to type / Open type |
Ctrl+Shift+B |
Ctrl+N |
| Introduce/Extract variable |
Alt+Shift+L |
Ctrl+Alt+V |
| Refactor menu |
Alt+Shift+T |
Ctrl+Shift+R |
| Shortcuts menu |
Ctrl+Shift+L |
- |
6. Some useful links
1. ReSharper documentation, including keymappings for both the IntelliJ and the Visual Studio mapping. Print a copy of the PDF version.
http://www.jetbrains.com/resharper/documentation/index.jsp
2. Dave Ford's Programming Blog: 10 IDE Shortcuts Everyone Should Know. Shows a couple of common operations in Eclipse and IntelliJ IDEA.
http://dave-ford.blogspot.com/2006/11/10-ide-shortcuts-everyone-should-know.html
3. For those of you wanting to read more about TDD:
http://www.agiledata.org/essays/tdd.html
4. Lars Vogel's JUnit Tutorial - For those of you that want to know more about how unit testing works. In this case, through JUnit and Java.
http://www.vogella.de/articles/JUnit/article.html
5. NUnit Quickstart - For those of you that want to know more about how unit testing works. In this case, through NUnit and .NET (C# to be specific). Not the best tutorial out there, but it's a quick way to discover the basics.
http://www.nunit.org/index.php?p=quickStart&r=2.4
... Long post. Congratulations if you made it all the way here!