1. Introduction
Some time ago, I held some evening seminars about C++. I tried to mix my own experiences with inspiration drawn from other sources, such as colleagues, the C++ 11 standard and Scott Meyer's Effective C++.
Overall, the seminars went well, and I'm currently combining the material into a one-day workshop for Edument (where I work). One of the highlights of the seminars was the "What's new in C++ 11, and what compiler support do we have?"-part.
In this article, I'll share some of the highlights, such as my own personal favorite additions to the language. When doing my research for the seminars and putting the material together, I spent a lot of time reading the C++ 11 standard. While the standard is very detailed, it's not always the best place to go for learning. At the same time, I had some trouble finding short and concise sources for syntax-lookup for some of the newer features. So, instead of writing a lengthy article about a certain feature (there's a lot of articles and tutorials out there that does that perfectly well), I'll try and present the features by showing the usage as soon as possible, followed by a small description/example.
This is by no means an exhaustive list of the C++ 11 standard. This is merely some of the points of my talks. I will cover the following points:
- New keyword - nullptr
- Type inference - Redefinition of auto
- Lambdas
- Varied smart pointers and the deprecation of auto_ptr
2. Features
So, without further ado, I'll list some of the new features of the C++ 11 standard in this section. I'll try to start each feature with a small code listing, showing how to use it, followed by a little more detail.
2.1 - New keyword - nullptr
In order to create a null pointer, we can now do the following:
char* varName = nullptr;
Before this, we simply used NULL or even 0. Basically, NULL is a remnant macro from C that made its way into C++ as well. The C++ definition varies slightly. For instance, by checking the header file stddef.h in GCC, you'll find (amongst other things) the following:
#ifndef __cplusplus
#define NULL ((void *)0)
#else /* C++ */
#define NULL 0
So, in C, we define NULL as ((void *)0), and in C++, we simply define it as 0. This means that the NULL macro could be interpreted as an integer as well. This could have some odd side effects from time to time. Consider the following simple example, where we're writing a template class:
template <typename T>
class MyType {
private:
// ...
public:
void MyMethod(T input) {
if (input == NULL) {
cout << "NULL pointer!" << endl;
}
else {
cout << "Not a NULL pointer" << endl;
}
}
};
This class is making a small (and perhaps not entirely sane) assumption, namely that we're working with a pointer. In reality, nothing stops us from creating a MyType<int> as well. Since the NULL macro expands as 0 or 0L, the check input == NULL would still work, even though we're using an int (or anything else that is comparable with an integer). This could either compile past this point, and (in best case) throw a compiler error at a later point, or (worse) give us hard-to-track-down runtime errors. In this case, nullptr is usable. Substituting NULL with nullptr will instead give us a compiler error since this check will fail when instantiating the template: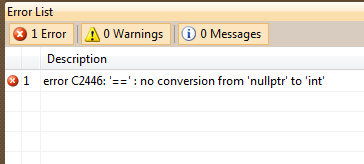 |
| Figure 1: nullptr to the rescue |
This is obviously just a small example, but the idea is to show that we get a mismatch between the NULL macro and the idea of a null pointer.
2.2 - Type inference - Redefinition of auto
Yes, C++ now has type inference, meaning we don't have to explicitily instruct the compiler about the type when declaring variables. Its basic usage is:
auto varName = someInstance.GiveMeSomething();
The auto keyword has been redefined. In previous versions, its usage has been to declare an automatic variable, meaning a variable whose lifetime is bound to its scope. Sounds familiar? It probably should, since this is the default behaviour for every variable created on the stack in C++. When was the last time you actually (explicitily) declared an variable as automatic?
One situation (out of many), where I find this useful, is when declaring stuff like iterators. It's quite nice to use with lambdas as well (as we shall see later). For instance. Suppose we want to iterate over an STL-list and want to declare an iterator:
list<string>::iterator beginIter = names.begin();
... Well, now we could do the following instead:
auto beginIter = names.begin();
But type inference is not only syntactic sugar. As shown in the C++ 0x FAQ by Bjarne Stroustrup, this is even more valuable when the exact type is more or less impossible (or at least hard) for the programmer to deduct. Consider the following example (borrowed from the aforementioned FAQ):
template<typename T, typename U>
void multiply(const vector<T>& vt, const vector<U>& vu)
{
// ...
auto tmp = vt[i]*vu[i];
// ...
}
The elements in the input vectors are of type T and type U. We're multiplying two elements and assigning the result to a temporary variable (tmp). The type of this variable is dependent on the typenames. In this case, auto is an invaluable tool to deduce the type of tmp depending on the actual template parameters.
I received some mixed comments whether type inference is too obscuring or not. Personally, I love it. It reminds me a lot of the type inference in C# (using the var keyword). It forces you to think your variable naming through and actually give them semantically meaningful names.
2.3 - Lambdas
Basic syntax:
[](){}; // Implicit return type
[]() -> return_type {}; // Explicit return type
Lambdas in C++ serve a very useful purpose. Basically, we're talking about anonymous functions with the ability to capture variables in the scope where the lambda is defined. This means that we can use C++ lambdas as closures (or not, if we prefer that). This is a concept not so much from the object oriented paradigm, but from functional programming.
The ABSOLUTELY simplest case (which will actually compile) is:
[](){};
The square brackets is called the capture clause. Here, you'll define which variables from the outlying scope you want to capture (meaning: have access to inside the lambda). For instance, to capture everything by reference or by value, we would do the following:
[&](){}; // Capture everything by reference
[=](){}; // Capture everything by value
The parentheses are the function argument list and the curly brackets are the method body. The return type is either infered from usage or explicit from the declaration. A few quick examples:
Lambda example 1:
// An alternative to function pointers,
// Combined with the auto keyword:
auto add = [](int a, int b){ return a+b; };
int sum = add(4,5);
Lambda example 2:
// Same as before, explicit return type:
auto add = [](int a, int b) -> int{ return a+b; };
int sum = add(4,5);
Lambda example 3:
// Capturing all local variables as references
auto myLambda = [&]() -> int{ // Body };
// ... And as values:
auto myLambda = [=]() -> int{ // Body };
Lambda example 4:
// Capturing one external variable by reference,
// and one by value:
int x = 5;int y = 10;
// Defining the lambda
auto lambda = [&x, y]() {
x++; // OK
y++; // Not OK
};
2.3.1 - When to use lambdas
I tend to use lambdas instead of C++ Functors (and function/function pointers). For instance, when iterating with a for_each loop. I normally did the following in C++ 98:
list<int> values; MyFunctor func; // ... Populate "values" // Iterate collection for_each(values.begin(), values.end(), func);
... Where MyFunctor was a function object on the following form:
class MyFunctor {
public:
void operator()(int obj) {
// Do stuff here on each iteration
}
};
Since lambdas, this iteration has now been reduced to:
for_each(values.begin(), values.end(), [&](){
// Do stuff here on each iteration
});
There ARE still scenarios when we might want to use something else than a lambda, of course. But nevertheless, it's a nice and powerful feature which I'll gladly use.
2.4 - Varied smart pointers and the deprecation of auto_ptr
Smart pointers has been around for some time. Basically, we're wrapping raw pointers in a class that can be created as an automatic variable instead, leaving cleanup to the destructor call when we're running out of scope.
We've hade the auto_ptr for some time (with all its flaws). For instance, the semantics of auto_ptr means a strict ownership; If you try to copy one auto_ptr to another, the first auto_ptr give its ownership up to the second one. If the second auto_ptr already owns a resource, this will get freed up first. This meant that some algorithms (such as some sort algorithms in the standard library) that relied upon making local copies of elements stopped working correctly.
Anyway: auto_ptr is being deprecated in favour of unique_ptr. We also have access to yet another smart pointer type called shared_ptr. They both have their background in the Boost library. Their basic usage is:
unique_ptr<SomeType> uPtr(new SomeType(5)); shared_ptr<SomeType> sPtr = make_shared<SomeType>(5);The basic idea of these pointers is the same as before: We're wrapping a raw pointer in another class. Since we're creating uPtr and sPtr as ordinary variables, we're creating them on the stack, not the heap, meaning their destructors will get called automatically when they're running out of scope. The wrapped raw pointer is created on the heap, but will get deleted as soon as the unique_ptr instance is destroyed. A really nice feature with this design is that we're taking advantage of the C++ stack unwinding, meaning we're cleaning up our resources even if an exception is thrown (this is not the case with raw pointers).
Other than that, the major difference between shared_ptr and unique_ptr is that shared_ptr allows several shared pointers to contain the same pointer. It keeps track of the number of instances with an internal counter which decreases everytime a shared pointer goes out of scope. The actual resource is not cleaned up until the last shared_ptr has exited its scope (setting the counter to 0).
A unique_ptr instance on the other hand, has the same idea of strict ownership as the auto_ptr, but with one major difference. While you COULD "copy" an auto_ptr (or rather: give the resource up), the assignment operator of the unique_ptr is non-public, meaning you'll get a compiler error if you try to assign it. This is definitely an improvement over auto_ptr.
Bottom line: Avoid raw pointers. Use smart pointers.
3. Conclusion
As I said in the beginning of this article, this is not an exhaustive list of C++ 11 features. Far from it. I've not even touched some of the larger areas, such as threads or variadic templates. The things that I've talked about in this post is relatively small changes, but still something that could have a huge impact on your code. I for one, don't write for_each-loops without using lambda expressions anymore. It would have been fun to write about more features and add more examples and descriptions, but this is starting to be quite a long blog post. I might write another C++ article in the future though :)
4. Useful links from the article
The following links has been present in the article. They provide content for reading more in-depth about everything that I've written about in this article.